

Chihuahua vs Muffin
By Blake Laufer
Author’s Note: I was fortunate to present at the recent CPA Virtual Conference on the topic of AI, data, and video analytics in parking. As a result of that presentation I was asked to expand on the topic for an article.
According to professor Pedro Domingo at the University of Washington: “People worry that computers will get too smart and take over the world… but the real problem is that computers are too stupid and they’ve already taken over the world.”
Parking managers recognize the need to have data for decision-making. When meeting with colleagues or bosses every decision needs to be supported by charts and graphs and data to garner support. The good old days management by intuition and experience are gone.
Computing systems, and especially those we find in parking operations, are wonderful at collecting massive quantities of raw data. But raw data isn’t useful to the typical parking manager; the data needs to be converted into information before it is useful.
Raw data is a raw material like iron ore, while processed data is like finished metal, something that can be used for productive ends.
Artificial intelligence comes in a variety of forms including natural language processing (“OK Google…”), making recommendations such as what to purchase on Amazon or what to watch on Netflix, and even predictive analytics (hurricane forecasting).
In parking there is one type of AI that we encounter the most, machine learning.
Machine learning is an application of pattern matching. That is, if you show the computer enough patterns then it becomes able to detect and predict that pattern in new data that it has never seen. A simple pattern may only need 10 or 20 inputs before the machine starts to recognize it. A complex pattern might require hundreds of thousands of inputs before the computer can predict a pattern.
We are used to computers following instructions written by humans, but that’s not how AI systems work. In a machine learning application, the computer is left to its own devices to analyze the many inputs, called training data, and look for patterns on its own based on tagged inputs.
For example, if you want a computer to recognize images of cats you must provide many thousands of images of cats, as well as some images that do not include cats. Each image is already identified (tagged) as “cat” or “not cat” so the computer can look for similarities in photos of cats, and dissimilarities of photos without cats. It will come up with its own concept of a what it perceives as a cat. It might look at the ratio of eyes-to-nose spacing, or the shape of the ears, or any number of other features.
The input data defines the programming, so training a system with different images will result in a different interpretation of what is a cat. If the training data is skewed – too many orange cats and not enough black ones – then the system’s future recognition of cats will be biased.
In parking one of the most common machine learning applications is license plate recognition (LPR). From the image of a license plate the computer magically converts the plate to text. What happens inside the magic comes from machine learning, the result of training the computer with many thousands of inputs to recognize letters, shapes, colours, angles, ratios, backgrounds, and other elements.
This still doesn’t prevent users from gaming the system. Similar letters make it harder for LPR to differentiate between letters. License plates like “B88B8BB” and “QOQQOQ” and “S5SSS5S” and “Z7Z2Z27” are real plates with a sole purpose of thwarting LPR systems.

The quality of the training data has a big impact on the accuracy of the machine learning prediction accuracy. Consider the images of the chihuahua and the muffin provided here. A human, even a young child, can decipher the differences here, but a computer really struggles. It needs more and more data, perhaps a million pictures of chocolate-blueberry muffins and chihuahuas – every one of them individually tagged “this is a muffin” or “this is a chihuahua” before the computer becomes accurate differentiating between the two.
Where does one go to find people willing to tag millions of images for training an AI system? It turns out that Google, amongst other companies, is already having you train their systems – for free.
The CAPTCHA is a tool used to distinguish humans from computers (Completely Automated Public Turing test to tell Computers and Humans Apart). In the case of Google, they use images from their Google Street View function in their Google Maps service. The CAPTCHA asks the human to click on all the images with street signs, bridges, storefronts, or some other element on which Google wants to train their AI. When enough humans identify the same elements, these go into the training database as tagged data. And voilà, millions of images tagged for free by unwitting humans.
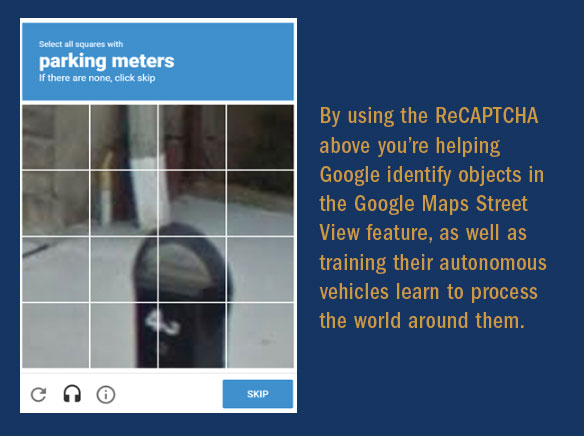
Parking operations do not have the luxury of millions of users willing to tag our data for free. But parking operations do generate vast amounts of data from our systems. It is possible to use this data in machine learning applications to make parking smarter.
In addition to license plate recognition there are a variety of applications in parking that leverage AI and machine learning.
Finding and counting vehicles in an image is a simple way to determine occupancy and availability without sending a human to view the lot. Parking operations can use security cameras or webcams to capture images, and then use AI tools to get accurate counts all day long.
While individual counts can be considered raw data, gathering counts over a period of minutes or hours becomes useful information. Key performance indicators like dwell time, turnover, peak and average occupancy all require good counts and individual points in time.
For the last several years parking operations have talked about “dynamic pricing”. The concept of dynamic pricing is simply to change the price of your product based on demand – higher when demand is high, and the product is scarce, and lower when demand is low, and the product is abundant.
Some believe that pricing should change hour-to-hour or minute-to-minute. While this may work in some industries (airline seat pricing, for example) most parking operations prefer more stability in pricing due to bylaw requirements, and the fact that most payment systems cannot handle rapid price changes.
Rudimentary applications of dynamic pricing have been around for years: parking facilities with “early bird” discounts are one example. Having a lot change for a metered price to a flat rate overnight is another. These are simply having different prices for the same product based on the target audience.
The key to success with dynamic pricing is having enough data to predict when prices should change. Each data sample includes the occupancy and current price, along with time of day, duration of stay, and perhaps other conditions like weather or location. These are the building blocks of measuring demand – or to be more accurate, the elasticity of demand.
Dynamic pricing is a perfect application of machine learning. With many hundreds or thousands of these data samples fed into a machine learning engine it is possible to predict the impact of price changes on the parking operation. The parking manager can model and anticipate the result of price changes without changing the price!
Of course the experienced parking manager would take a holistic approach to dynamic pricing, considering not just the revenue-maximizing nature of dynamic pricing, but also the effect on the number of citations written, or potential erosion of goodwill with the public, and any other number of invisibly connected factors.
In fact, most parking operations are already awash in data. Individual parking management systems such as PARCs, pay-by-cell, meters, LPR, occupancy counters, citations, and many others, all gather mountains of data that could feed a machine learning engine. That raw data, turned into actionable intelligence, could improve parking for both staff and patrons.
Additionally, organizations such as Alliance for Parking Data Standards (APDS), are working to develop uniformity around data exchange between parking systems so that it’s easier for parking operations to manage and measure their operations. (The APDS is a not-for-profit joint effort formed by the International Parking & Mobility Institute, the British Parking Association, and the European Parking Association.)
Parking operations are recognizing a need for staff members to be versed in having some ability to convert data into information. This can be training staff on the basics of databases and using pivot-tables in spreadsheets, or even bringing a full-time parking Business Analyst on staff.
And when human beings are better at overall data-wrangling, then maybe the computers that have taken over the world will be a little more intelligent too. ν
About the author: Blake Laufer is the founder of Mistall Insight Inc, providing count technologies and AI solutions for the parking industry. blake@mistall.com

{kind=link}